by Tim Messegee, senior director of solutions marketing, Rambus.
Why GDDR6 memory is a great choice for the next-generation of inference devices.
The current age of artificial intelligence (AI) is grounded in the dramatic advancements in machine learning (ML). We can think about AI/ML in its two principal parts: training and inference. The size and complexity of AI/ML training have been increasing at a breathtaking 10X per year, with the largest training models now exceeding a trillion parameters. The training of AI models happens in large data centers and will continue to do so for the foreseeable future, leveraging massively parallel architectures of AI accelerators and advanced servers. HBM memory, now in its third major generation, is the solution of choice for AI accelerators used for training. HBM’s price premium and higher implementation complexity are justified by its unmatched bandwidth performance.
Inference is the deployment side of AI/ML where we can make practical application of the models produced by the training process. Inference too is performed in the data center, but increasingly will move to the network edge and to end devices. Doing so improves latency, supporting real-time applications driven by AI.
For inference, the bandwidth demands are high (but not as extreme as in training), and the cost sensitivity is greater. Here, GDDR6 provides an excellent combination of bandwidth, ease of design, and cost- effectiveness to support a wide range of inference use cases.
The rise of GDDR
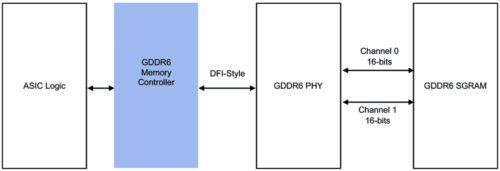
Graphics DDR (GDDR) was originally designed for the gaming and graphics market over two decades ago. GDDR has undergone several major evolutions in that time, with the latest generation, GDDR6 delivering data rates of up to 24 gigabits per second (Gbps). GDDR6 relies on the same high-volume manufacturing and assembly techniques used to produce standard DDR- type DRAM. More specifically, GDDR6 employs the traditional approach of connecting packaged and tested DRAMs together with an SoC through a standard PCB. Leveraging existing infrastructure and processes offers system designers a familiarity that reduces cost and implementation complexities.
GDDR6 employs a 32-bit wide interface with two independent 16-bit channels. Running at a data rate of 24Gbps, GDDR6 can deliver a per device memory bandwidth of 96 gigabytes per second (GBps). (The math works outas24Gbps*32*1 byte/8 bits = 96GBps.)
The principal design challenge for GDDR6 implementations derives from one of its strongest features: its speed. Maintaining signal integrity (SI) at speeds of 24Gb/s, particularly at lower voltages, requires significant expertise. Designers face tighter timing and voltage margins while the number of sources of loss and their effects all rise rapidly. Interdependencies between the behavior of the interface, package, and board require a method of co-design of these components to maintain the SI of the system.
On balance, the excellent performance characteristics of GDDR6 memory, built on tried-and-true manufacturing processes, is an ideal memory solution for AI inference. Its price-performance characteristics make it suitable for volume deployment across a broad array of edge network and end-point devices.
Looking forward
Given its tremendous benefits, AI development will not slow down. As such, the hunger for more memory bandwidth and capacity to enable greater computing power will be insatiable.
With scalability to 96GB/s of bandwidth per device, GDDR6 is well positioned to support inference accelerator designs in the years ahead. Beyond that, GDDR6 and the experience gained from its implementations will serve as the foundation for future generations of GDDR.