
In 2011, venture capital investor Marc Andreessen wrote an opinion piece for The Wall Street Journal titled “Why Software Is Eating the World.” As part of this, he noted that it took 10 years after the wide adoption of the internet—and the dot-com economic bubble—for the new technology to bear fruit and suggested that this timeframe could be applicable to similar technological developments.
In his opinion piece, Marc proposed that software was in the process of revolutionizing the entire human experience. The following 10 years showed how prescient he was. During the decade following Marc’s article, many established industries were disrupted by software. The laggards were replaced. Financial, industrial, agricultural, medical, entertainment, retail, healthcare, education, and defense were all touched and permanently changed by software.
Software was indeed eating the world.
The reaction to the adoption of various forms of artificial intelligence (AI) today leads us to predict a second revolution. According to McKinsey, Generative AI (GenAI) could add the equivalent of $2.6 trillion to $4.4 trillion annually across all industry sectors. “Generative AI is going to be as fundamental as the creation of the microprocessor, the personal computer, the internet, and the mobile phone,” says Microsoft Founder Bill Gates.
Marc’s prophetic headline was soon expanded to: “Software is eating the world, hardware is feeding it, and data is driving it.” Now, software is eating the hardware.
AI is built on complex algorithms whose execution is dominated by data movement, not by data processing that heavily taxes data throughput. The latest types of algorithms implemented in dense or large language models (LLM) called transformers consist of neural networks capable of learning context by tracking relationships in sequential data like the words in a sentence.
Initially, transformers were favored by car manufacturers for designing autonomous driving (AD) algorithms because of their ability to track and learn multiple complex interactions between the environment and the AD vehicle. Today, they are the foundation of GenAI technology.
Caution prevails. GenAI needs vast amounts of processing power and substantial data communication throughput that must be supported and delivered by the underlying hardware infrastructure. These demanding requirements are necessary to process billions of parameters on every clock cycle.
ChatGPT is living proof with more than 100 million users signed on in less than a year after launching. The number of parameters in the current GPT-4 generation is estimated to have increased to more than one trillion from the previous generation of 175 billion. This means that AI hardware accelerators must scale to handle anywhere from 175 billion to over a trillion parameters stored in memory to execute each user query.
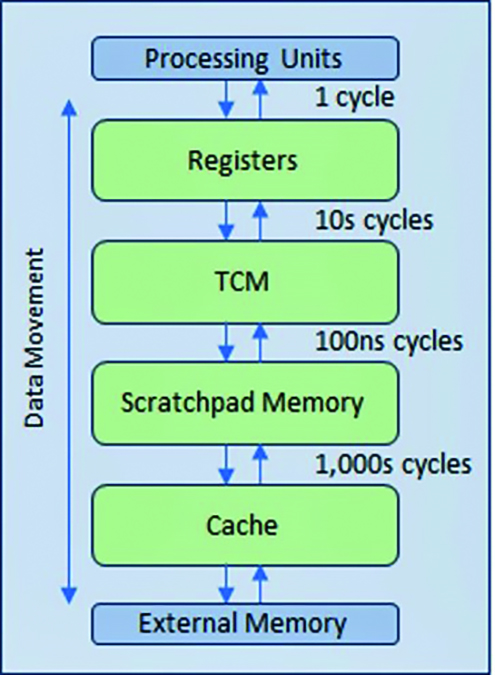
Computing architectures currently in use are not designed to handle this amount of data traffic between processor cores and memories that are typically implemented outside the computing cores. Central processing units (CPUs) are inadequate for the task. Graphics processing units (GPUs) have the performance but not the implementation efficiency.
In fact, almost all computing architectures are inadequate. They force processors to idle while waiting to receive data, especially with GPT-4 where idling is higher than 97% of the time. To put this another way, their efficiency is lower than 3%. A processor with a nominal computing power of one PetaOPS—1015 or 1,000,000,000,000,000 operations-per-second—at this efficiency level produces only about 30 TeraOPS of performance.
The root of the problem sits on the memory bottleneck commonly called the “memory wall,” which suggests improvements in processor performance far exceeds those of the memory. To address this bottleneck, the semiconductor industry devised a multi-level hierarchical memory cache that reduces data traffic with the slower main and external memories.
LMM model training and inference are typically handled by large and expensive computing farms that run for days, consume massive amounts of electric power, and generate voluminous amounts of unwanted heat. Inference processing on edge devices, a potential market for an unlimited number of applications, is further hindered by inadequate bandwidth, insufficient computational power, long latency, and excessive energy consumption.
As was noted earlier, ChatGPT-4’s model size has pushed into trillion+ parameters that must be stored in memory, causing the memory size requirement to move into terabytes territory. These parameters must be accessed simultaneously at high speed during training/inference, pushing memory bandwidth to hundreds of gigabytes or even terabytes per second. Processor efficiency of data transfer bandwidth between memory and processor is almost non-existent.
Power consumption is another consideration. Algorithms are executed on high-performance computing clusters, each consuming several kilowatts of power. The actual power consumption required to perform ChatGPT-4 user queries on a large-scale overloads power generating plants and overstresses energy distribution networks.
Obviously, investment in the hardware infrastructure has not kept up with ChatGPT or its energy consumption. Based on current purchasing options for processors, an estimate of the acquisition cost for a GPT-4 processing system running 100,000 queries/second—a benchmark established by Google search—would be in the ballpark of several hundred billion dollars. Meanwhile, the energy costs of running the hardware would be in the range of several hundred million dollars per day. Back-of-the-envelope calculations would lead to a cost per query of about ¢10 vis-à-vis ¢0.2 in a Google search.
As a result, any promise of unparalleled productivity from Generative AI is dashed with the current limitations of the hardware infrastructure costs.
A semiconductor industry call to action
The semiconductor industry has an opportunity to challenge the status quo with an improved hardware infrastructure built on an innovative processing architecture that needs to scale to accommodate a broad range of today algorithms and to be able to address future LLMs enhancements. Such an architecture ought to possess the following capabilities:
• More than one petaflop of processing power per device.
• Processing efficiency of 50% under massive workloads.
• Latency of less than two seconds per query.
• Power consumption of less than 50 watts per device.
• Costs of less than $100 per device.
This architecture should also adopt the latest manufacturing advancements, including the lowest process technology nodes and multi-chip stacking.
In summary, the cost effectiveness of an economically sustainable, energy-efficient processing system must increase by at least two orders of magnitude. Lowering the annual cost to run 100,000 queries per second on a GPT-4-type system from hundreds of billions of dollars to fewer than $10 billion will deliver the promise of GenAI and keep it from consuming its feeder.